High Availability (HA)/Clustering is available which allows two or more Virtual Appliances (VA) to be clustered for near real-time synchronization of the file-system and database. This aims to ensure that your backups and simulations continue to run even if there is an interruption of services on the primary appliance.
The clustering technologies involved are MariaDB Galera Cluster for the database replication, and GlusterFS for the filesystem replication. These maintain the synchronicity between all the configured nodes.
There are two configuration types available in the VA which are described below:
2-Node Cluster (from VA 3.5 to 4.9 - Not available from 5.1)
This uses two VAs in an active-passive configuration. The primary node will perform all operations while the secondary node remains inactive - until the primary node fails. The secondary node cannot be accessed until the primary has failed over.
Note: This configuration is prone to a condition called split-brain, otherwise known as network partitioning, if network connectivity is lost between the nodes, it is therefore not a recommended configuration if your VAs are in different fault zones, e.g. multiple datacentres, unless there are redundant links available.
3+ Node Cluster (from VA 4.8)
This uses multiple VAs in an active-active configuration. All VAs can continue to be accessed by their node address and any operation may be performed from any node in the cluster. The more nodes in the cluster the more resilient to failures the cluster becomes. Additional nodes may be added when needed.
Note: If deploying the cluster across multiple fault zones, e.g. two datacentres, one zone should contain more than 50% of the total nodes. For example; In a 5 node cluster - site A has 2 nodes and site B has 3 nodes. In the event that network connectivity between the zones is disrupted the cluster will remain operational in the zone that has the majority of the nodes (51+%).
HA/Clustering can be configured from the VA Options → Cluster Settings. When configuring clustering we would recommend deploying a new virtual appliance as the additional node.
In a 2-node cluster, when configuring the cluster, the appliance you are configuring from will become the primary node and all changes made to this node will be replicated to the secondary node.
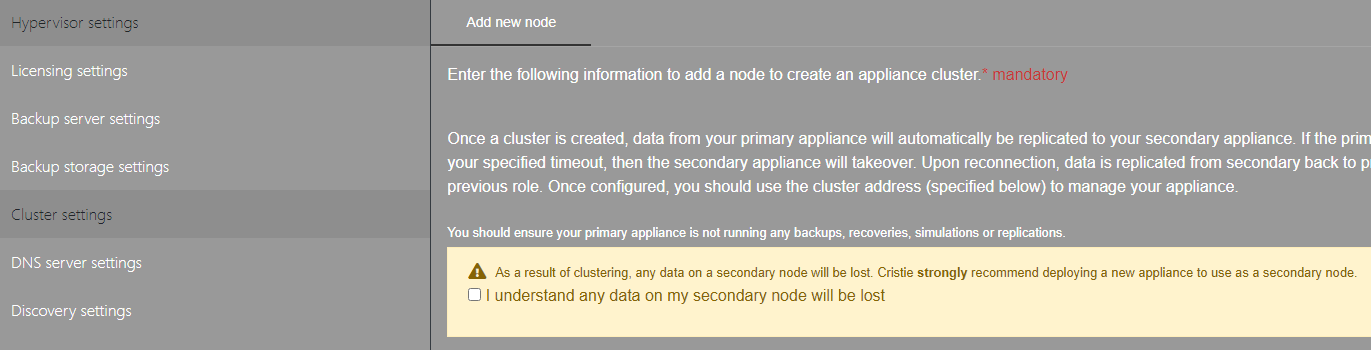
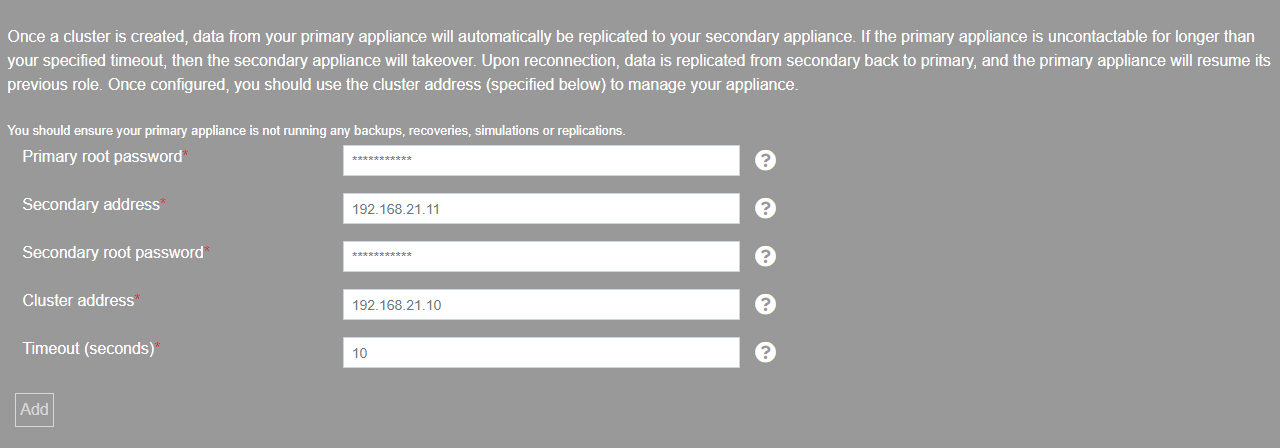
To proceed with clustering you will need to check that you understand that the secondary node data will be lost. When checked, you will be able to enter the credentials and addresses to be used for the secondary node and the cluster address.
In a 2-node cluster you can also configure the polling interval for the cluster heartbeat, if the heartbeat fails the cluster will begin transferring service responsibility to the secondary node.
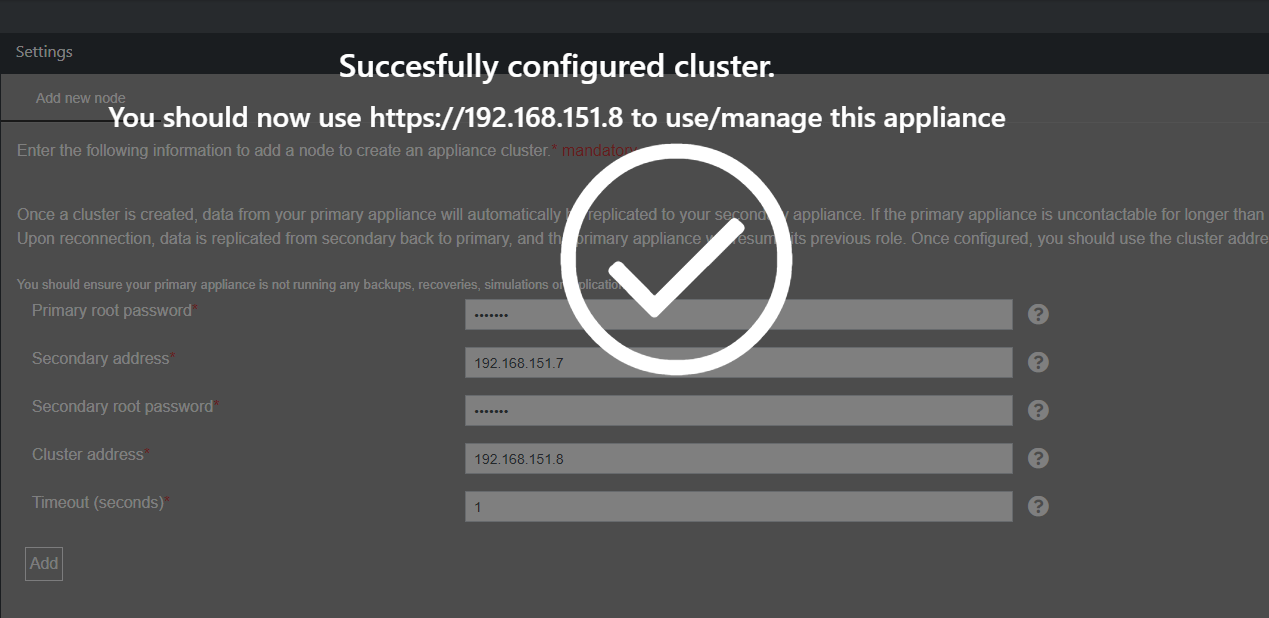
Once the cluster has been configured you will be presented with a success message.
Cluster shutdown, services restart, or failure considerations
In a 3+ node configuration the order that the nodes are started is important - this assumes all nodes are gracefully shutdown. The last node shutdown should be the first started and then the remaining nodes may be started in any order. This is because the last node shutdown will have the most up-to-date database state.
If the majority of the nodes (51+%) have failed and not enough nodes can be brought online to restore quorum, then it may be necessary to forcefully bring the cluster online. This can be done by running manual_cluster_options --start-mysql to bring the database online, and manual_cluster_options --start-gluster to restore connectivity with the clustered volumes.
Please note that running manual_cluster_options --start-gluster is destructive. Any offline bricks (brick being a node volume containing replica files) will be forcefully removed. This will require the node to be reverted and re-added after volume quorum is restored.
If all the cluster nodes have been shutdown, and the last node cannot be started first, then the MariaDB (MySQL) cluster can be started manually from any node by running manual_cluster_options --start-mysql. The other nodes should be started, or restarted, sequentially to synchronise the cluster.
If there is only a single, or two nodes, active in the current cluster then you must also run manual_cluster_options --start-mysql after restarting a node, or any node services using the command restart_services, on the most advanced node. This is because a single, or two node, cluster cannot achieve a quorum (majority).
manual_cluster_options CLI utility usage
This utility allows you to view the status of the MariaDB Galera Cluster and GlusterFS cluster, or perform specific operations to restore access if quorum is lost.
usage: manual_cluster_options [-h] [–start-mysql] [–start-gluster] [–remove-gluster-nodes] [–cluster-health]
Start MySQL and Gluster options if quorum is lost
optional arguments:
-h, --help — show this help message and exit
–start-mysql — Start MySQL using this node as the primary
–start-gluster — Start Gluster when quorum has been lost (i.e. unrecoverable nodes)
–remove-gluster-nodes — Specify which nodes should be removed. Requires --start-gluster
–cluster-health — Returns the status of the MySQL and Gluster clusters for this node